Issues With Common Software Quality Metrics
One of the goals of every business is to maximize profits. In the software world, this is done by minimizing development, testing, and operational costs. Companies are beginning to measure every aspect of the software lifecycle to identify areas for improvement.
Collecting metrics is a great thing. However, they’re often misinterpreted and result in misguided efforts. Let’s take a look at two common metrics.
Code Coverage
Code coverage indicates the amount of code that is covered when performing some sort of task. This task is often the execution of the entire test suite for that software. It’s represented by a percentage and can apply to different code granularities. For example, an invocation of a 10-line method may exercise 7 lines of code. The code coverage of this method would be 70%.
Unenlightened managers may incrementally push for high numbers like 80% code coverage with the reasoning that once they achieve 100% coverage, the code is perfectly tested. This assertion is wrong on many levels.
First, code coverage is often used synonymously with statement coverage. 100% statement coverage is inadequate and needs to be supplemented with branch and path coverage.
Let’s use a contrived example:
public static int someRandomFunction(boolean a, b, c) {
int x = 0;
if (a) {
x += 1;
}
if (b) {
x += 2;
}
if (c) {
x += 4;
}
return x;
}- statement coverage - For 100% statement coverage, simply pass in
truefora,b, andc. This will give you a return value of 7. - branch coverage - Full statement coverage doesn’t exercise all of the branching logic. In order to cover all of
the branches, an additional execution with
falseset fora,b, andcneeds to be performed. This would produce a return value of 0. - path coverage - And finally, full path coverages requires that this method be called with all combinations of
trueandfalsefora,b, andc. This would produce return values of 0 through 7.
As you can see, having 100% statement coverage does not mean the code is fully tested. At this point, one might argue that it seems reasonable to ask for good statement, branch, and path coverage. It’s time and resource expensive to do this. Why test code that only runs once in a blue moon?
As an alternative, I propose that only the heaviest code paths be tested and covered. Instrument your software and let users play with it. Then, identify the most trodden paths and add tests for those cases. Frequently assess the quality of tests for these areas using mutation testing to ensure that they are resilient to software modifications.
Cyclomatic Complexity
Cyclomatic complexity is a metric to determine how complex software is. It’s a representation of how many paths a code section can have. The higher the number, the more complex the section is. The originator of this metric determined that modules should be refactored once they approach a cyclomatic complexity of 10. The goal in many software organizations is to minimize this number because complex software is hard to reason about and is positively correlated with the number of defects.
The following has a cyclomatic complexity of 1 since there are no paths to be taken.
public static void countToTen() {
for (int x = 1; x <= 10; x++) {
System.out.println(x);
}
}However, sometimes software needs to be complex. Take a look at the business logic behind determining filing status for American taxes:
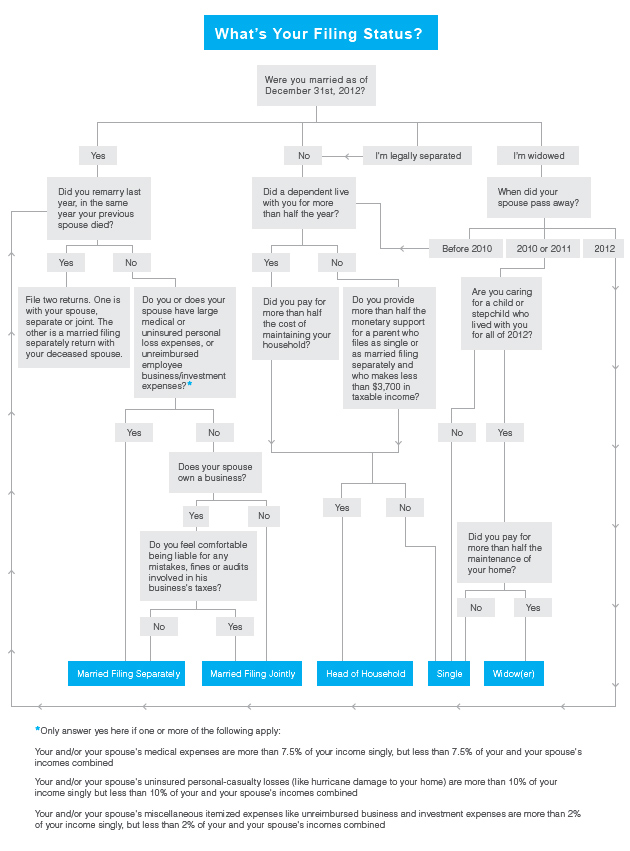
(image from http://www.learnvest.com/knowledge-center/how-to-decide-your-filing-status/)
The cyclomatic complexity of this is at least 10 and it can’t be reduced. What is even more mind boggling is that this is simply the first step in most tax software. Like before, we pose the same question. Why would you focus on reducing the complexity of code that is rarely called?
The more balanced approach here is to compare the cyclomatic complexity against its functionality. A piece of code that is
doing something complicated should have a high number and conversely, simple functionality should have a lower number. As a
benchmark, the ajax function in the popular jQuery library has a cyclomatic complexity of 31.
Quality Assistance
Despite these shortcomings, all of these metrics still have some value. Don’t blindly assume that maximizing or minimizing them for your code base will give you the quality assurance you need. Think of these metrics as tools for quality assistance and apply them to the most utilized areas of your code.